Hello everyone! It’s been a while, and although I’ve been keeping up with what’s happening in the AI world, I haven’t really had time to post new releases. I’ve also decided to change a form, and for some time I’ll be doing just the links instead of links + summaries. Let me know how you like the new form. I think it’s more useful, because in most cases you get the summary of the article from the beginning. Since this is a “resurrection” of this newsletter, I’ve tried to include some of the most important news from the last 5 months in AI security here. Also, I’ve started using the tool that detects if the LLM was used to create the content – this way I’m trying to filter out low quality content created with LLMs (I mean, if the content is created with ChatGPT, you could create it yourself, right?).
If you find this newsletter useful, I’d be grateful if you’d share it with your tech circles, thanks in advance! What is more, if you are a blogger, researcher or founder in the area of AI Security/AI Safety/MLSecOps etc. feel free to send me your work and I will include it in this newsletter 🙂
Here comes another edition of my newsletter. I’ve collected some interesting resources on AI and LLM security – most of them published in the last two weeks of September.
If you are not a subscriber yet, feel invited to subscribe here.
Also, if you find this newsletter useful, I’d be grateful if you’d share it with your tech circles, thanks in advance!
Autumn-themed thumbnail generated with Bing Image Creator 🙂
LLM Security
OpenAI launches Red Teaming Network
OpenAI announced an open call for OpenAI Red Teaming Network. In this interdisciplinary initiative, they want to improve the security of their models. Not only do they invite red teaming experts with backgrounds in cybersecurity, but also experts from other domains, with a variety of cultural backgrounds and languages.
I am building a payloads’ set for LLM security testing
Shameless auto-promotion, but I’ve started working on PALLMS (Payloads for Attacking Large Language Models) project, within which I want to build huge base of payload, which can be utilized while attacking LLMs. There’s no such an initiative publicly available on the Internet, so that’s a pretty fresh project. Contributors welcome!
LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins
In this paper (by Iqbal, et. al.) authors review the security of ChatGPT plugins. That’s a great supplement for OWASP Top10 for LLM LLM:07 – Insecure Plugin Design vulnerability. Not only have authors analyzed the attack surface, but also they demonstrated potential risks on real-life examples. In this paper, you will find an analysis of threats such as: hijacking user machine, plugin squatting, history sniffing, LLM session hijacking, plugin response hallucination, functionality squatting, topic squatting and many more. The topic is interesting and I recommend this paper!
Wunderwuzzi – Advanced Data Exfiltration Techniques with ChatGPT
In this blog post, awesome @wunderwuzzi presents a variety of techniques for ChatGPT chat history data exfiltration by combining techniques such as indirect prompt injection and using plugins in a malicious way.
Security Weaknesses of Copilot Generated Code in GitHub
In this paper, Fu, et. al. analyze security of the code generated using GH copilot. I will just paste a few sentences from the article’s summary:
“Our results show: (1) 35.8% of the 435 Copilot generated code snippets contain security weaknesses, spreading across six programming languages. (2) The detected security weaknesses are diverse in nature and are associated with 42 different CWEs. The CWEs that occurred most frequently are CWE-78: OS Command Injection, CWE-330: Use of Insufficiently Random Values, and CWE-703: Improper Check or Handling of Exceptional Conditions (3) Among these CWEs, 11 appear in the MITRE CWE Top-25 list(…)”
Review your code – either from Copilot or from ChatGPT!
Can LLMs be instructed to protect personal information?
In this paper, the authors announced PrivQA – “a multimodal benchmark to assess this privacy/utility trade-off when a model is instructed to protect specific categories of personal information in a simulated scenario.”
Bing Chat responses infiltrated by ads pushing malware
As Bing Chat is scraping the web, malicious ads have been detected to be actively injected into its responses. Kind of reminds me of an issue I’ve found in Chatsonic in May ’23.
The American National Security Agency has just launched a hub for AI security – The AI Security Center. One of the goals is to create the risk frameworks for AI security. Paul Nakasone, the director of the NSA, proposes an elegant definition of AI security: “Protecting systems from learning, doing and revealing the wrong thing”.
In this paper, researchers have proven that the detectors of AI-generated images have multiple vulnerabilities and there isn’t a good way for proving if the image is real or generated by the AI. “Our attacks are able to break every existing watermark that we have encountered” – said the researchers.
A critical vulnerability has been found in TorchServe – PyTorch model server. This vulnerability allows access to proprietary AI models, insertion of malicious models, and leakage of sensitive data – and can be used to alter the model’s results or to execute a full server takeover.
Here’s a visual explanation of this vulnerability from BleepingComputer:
Can Large Language Models Provide Security & Privacy Advice? Measuring the Ability of LLMs to Refute Misconceptions
In this paper, the conclusion is that LLMs are not the best tool to provide S&P advice, but for some reason, the researchers (Chen, Arunasalam, Celik) haven’t tried to either fine-tune the model using fine-tuning APIs, or to use embeddings – thus, I believe the question remains kind of open. In my opinion, if you fine-tune the model on your knowledge base or if you create some kind of embedding of your data, then the quality of S&P advice should go up.
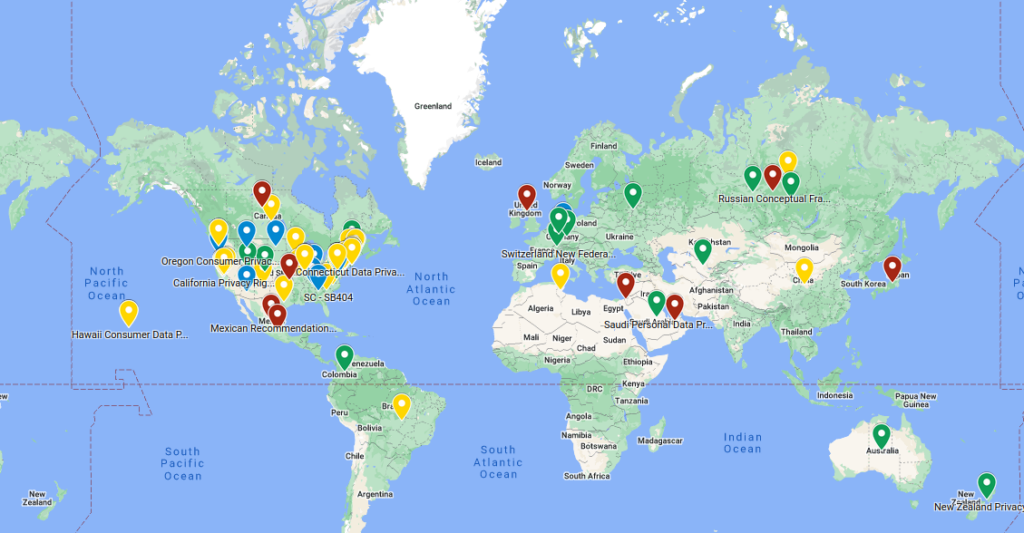
Fairly AI team have done this super cool work and published a map of AI regulations all over the world. Useful for anyone working with a legal side of AI!
The map legend:
Green: Regulation that’s passed and now active.
Blue: Passed, but not live yet.
Yellow: Currently proposed regulations.
Red: Regions just starting to talk about it, laying down some early thoughts.
Exploring the Dark Side of AI: Advanced Phishing Attack Design and Deployment Using ChatGPT, Begoulink, et. al., link: https://arxiv.org/pdf/2309.10463.pdf
Here comes the fourth release of my newsletter. This time I have included a lot of content related to the DEFCON AI Village (I have tagged content that comes from there) – a bit late, but better later than never. Anyway, enjoy reading.
Also, if you find this newsletter useful, I’d be grateful if you’d share it with your tech circles, thanks in advance!
Any feedback on this newsletter is welcome – you can mail me or post a comment in this article.
AI Security
Model Confusion – Weaponizing ML models for red teams and bounty hunters [AI Village]
This is an excellent read about ML supply chain security by Adrian Wood. One of the most insightful resources on the ML supply chain that I’ve seen. Totally worth reading!
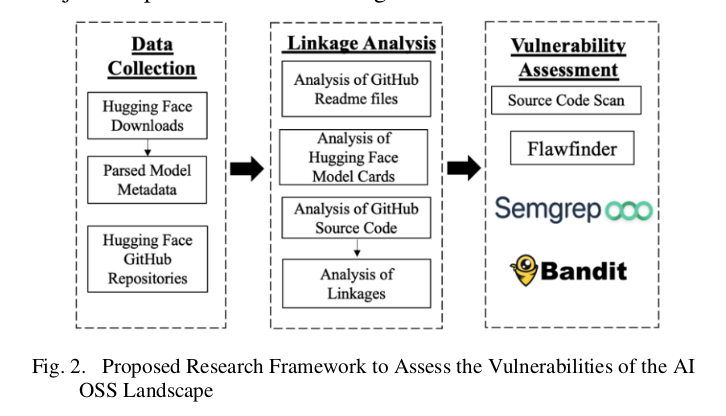
Assessing the Vulnerabilities of the Open-Source Artificial Intelligence (AI) Landscape: A Large-Scale Analysis of the Hugging Face Platform [AI Village]
Researchers have performed automated analysis of 110 000 models from Hugging Face and have found almost 6 million vulnerabilities in the code.
LLM Legal Risk Management, and Use Case Development Strategies to Minimize Risk [AI Village]
Well, I am not a lawyer. But I do know a few lawyers who read this newsletter, so maybe you will find these slides on the legal aspects of LLM risk management interesting 🙂
This thing was on the Internet for a while, but for some reason I’ve never seen it. LLM Hacker’s Handbook with some useful techniques of Prompt Injection and proposed defenses.
Initially, this newsletter was meant to be exclusively related to security, but in the last two weeks I’ve stumbled upon a few decent resources on LLMs and AI and I want to share them with you!
In this section you’ll find some links to recent AI security and LLM security papers that I didn’t manage to read. If you still want to read more on AI topics, try these articles.
“Does Physical Adversarial Example Really Matter to Autonomous Driving? Towards System-Level Effect of Adversarial Object Evasion Attack”
This is the second release of my newsletter. I’ve collected some papers, articles and vulnerabilities that were released in last two weeks, this time the resources are categorized into following categories: LLM Security, AI Safety, AI Security. If you are not a mail subscriber yet, feel invited to subscribe: https://hackstery.com/newsletter/.
Order of the resources is random.
Any feedback on this newsletter is welcome – you can mail me or post a comment in this article.
LLM Security
Image to prompt injection in Google Bard
“Embrace The Red” blog on hacking Google Bard using crafted images with prompt injection payload.
AVID ML (AI Vulnerability Database) Integration with Garak
Garak is a LLM vulnerability scanner created by Leon Derczynski. According to the description, garak checks if an LLM will fail in a way we don’t necessarily want. garak probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. AvidML supports integration with Garak for quickly converting the vulnerabilities garak finds into informative, evidence-based reports.
Limitations of LLM censorship and Mosaic Prompt attack
Although censorship brings negative associations, in terms of LLMs it can be used to prevent LLM from creating malicious content, such as ransomware code. In this paper authors demonstrate attack method called Mosaic Prompt, which is basically splitting malicious prompts into sets of non-malicious prompts.
Universal and Transferable Adversarial Attacks on Aligned Language Models
Paper on creating transferable adversarial prompts, able to induce objectionable content in the public interfaces to ChatGPT, Bard, and Claude, as well as open source LLMs such as LLaMA-2-Chat, Pythia, Falcon, and others. This paper was supported by DARPA and the Air Force Research Laboratory.
Survey on extracting training data from pre-trained language models
Survey based on more than 100 key papers in fields such as natural language processing and security, exploring and systemizing attacks and protection methods.
Amazon, Anthropic, Google, Inflection, Meta, Microsoft and OpenAI have agreed to self-regulate their AI-based solutions. In these voluntary commitments, the companies pledge to ensure safety, security and trust in artificial intelligence.
Anthropic’s post on red teaming AI for biosafety and evaluating models capabilities i.e. for ability to output harmful biological information, such as designing and acquiring biological weapons.
According to documentation: “It empowers engineers and developers to build pipelines to export outcomes of tests in their ML pipelines as AVID reports, build an in-house vulnerability database, integrate existing sources of vulnerabilities into AVID-style reports, and much more!”
The article from Mandiant on securing the AI pipeline. Contains GAIA (Good AI Assessment) Top 10, a list of common attacks and weaknesses in the AI pipeline.
“In this paper, we dive deeper into SAIF to explore one critical capabilitythat we deploy to support the SAIF framework: red teaming.This includes three important areas: 1. What red teaming is and why it is important 2. What types of attacks red teams simulate 3. Lessons we have learned that we can share with others”
MIT researchers have developed a technique to protect sensitive data encoded within machine learning models. By adding noise or randomness to the model, the researchers aim to make it more difficult for malicious agents to extract the original data. However, this perturbation reduces the model’s accuracy, so the researchers have created a framework called Probably Approximately Correct (PAC) Privacy. This framework automatically determines the minimal amount of noise needed to protect the data, without requiring knowledge of the model’s inner workings or training process.
I am working on a practical course for professionals who want to break, hack, and harden LLM-powered apps – based on the OWASP Top 10 for LLMs and real-world experience testing AI systems in the wild.




 Green: Regulation that’s passed and now active.
Green: Regulation that’s passed and now active. Blue: Passed, but not live yet.
Blue: Passed, but not live yet. Yellow: Currently proposed regulations.
Yellow: Currently proposed regulations. Red: Regions just starting to talk about it, laying down some early thoughts.
Red: Regions just starting to talk about it, laying down some early thoughts.