Here comes the fourth release of my newsletter. This time I have included a lot of content related to the DEFCON AI Village (I have tagged content that comes from there) – a bit late, but better later than never. Anyway, enjoy reading.
Also, if you find this newsletter useful, I’d be grateful if you’d share it with your tech circles, thanks in advance!
Any feedback on this newsletter is welcome – you can mail me or post a comment in this article.

AI Security
- Model Confusion – Weaponizing ML models for red teams and bounty hunters [AI Village]
This is an excellent read about ML supply chain security by Adrian Wood. One of the most insightful resources on the ML supply chain that I’ve seen. Totally worth reading!
Link: https://5stars217.github.io/2023-08-08-red-teaming-with-ml-models/
- Assessing the Vulnerabilities of the Open-Source Artificial Intelligence (AI) Landscape: A Large-Scale Analysis of the Hugging Face Platform [AI Village]
Researchers have performed automated analysis of 110 000 models from Hugging Face and have found almost 6 million vulnerabilities in the code.
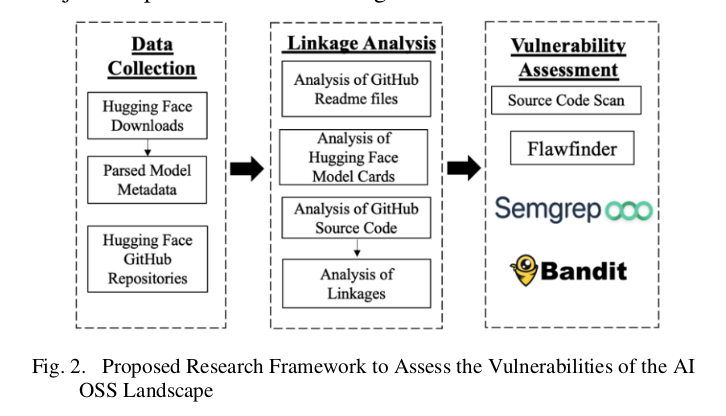

Links: slides: https://aivillage.org/assets/AIVDC31/DSAIL%20DEFCON%20AI%20Village.pdf paper: https://www.researchgate.net/publication/372761501_Assessing_the_Vulnerabilities_of_the_Open-Source_Artificial_Intelligence_AI_Landscape_A_Large-Scale_Analysis_of_the_Hugging_Face_Platform
- Podcast on MLSecOps [60 min]
Ian Swanson (CEO of Protect AI) & Emilio Escobar (CISO of Datadog) are talking about ML & AI Security, MLSecOps, Supply Chain Security and LLMs:
Link: https://shomik.substack.com/p/17-ian-swanson-ceo-of-protect-ai
Regulations
- LLM Legal Risk Management, and Use Case Development Strategies to Minimize Risk [AI Village]
Well, I am not a lawyer. But I do know a few lawyers who read this newsletter, so maybe you will find these slides on the legal aspects of LLM risk management interesting 🙂
Link: https://aivillage.org/assets/AIVDC31/Defcon%20Presentation_2.pdf
- Canadian Guardrails for Generative AI
Canadians have created a document with a set of guardrails for developers and operators of Generative AI systems.
LLM Security
- LLMSecurity.net – A Database of LLM-security Related Resources
Website by Leon Derczynski (LI: https://www.linkedin.com/in/leon-derczynski/ ) that catalogs various papers, articles and news regarding
Link: https://llmsecurity.net/
- LLMs Hacker’s Handbook

This thing was on the Internet for a while, but for some reason I’ve never seen it. LLM Hacker’s Handbook with some useful techniques of Prompt Injection and proposed defenses.
Link: https://doublespeak.chat/#/handbook
AI/LLM as a tool for cybersecurity
- ChatGPT for security teams [AI Village]
Some ChatGPT tips & tricks (including jailbreaks) from GTKlondike (https://twitter.com/GTKlondike/)
Link: https://github.com/NetsecExplained/chatgpt-your-red-team-ally
Bonus: https://twitter.com/GTKlondike/status/1697087125840376216
AI in general
Initially, this newsletter was meant to be exclusively related to security, but in the last two weeks I’ve stumbled upon a few decent resources on LLMs and AI and I want to share them with you!
This post by Stephen Wolfram on how does ChatGPT (and LLMs in general) work:
https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
Update of GPT 3.5 – fine-tuning is now available through OpenAI API:
https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates
This post by Chip Huyen on how does RLHF work: https://huyenchip.com/2023/05/02/rlhf.html and this one from Huggingface: https://huggingface.co/blog/rlhf
Some loose links
In this section you’ll find some links to recent AI security and LLM security papers that I didn’t manage to read. If you still want to read more on AI topics, try these articles.
“Does Physical Adversarial Example Really Matter to Autonomous Driving? Towards System-Level Effect of Adversarial Object Evasion Attack”
Link: https://arxiv.org/pdf/2308.11894.pdf
“RatGPT: Turning online LLMs into Proxies for Malware Attacks”
Link: https://arxiv.org/pdf/2308.09183.pdf
“PENTESTGPT: An LLM-empowered Automatic Penetration Testing Tool”
Link: https://arxiv.org/pdf/2308.06782.pdf
“DIVAS: An LLM-based End-to-End Framework for SoC Security Analysis and Policy-based Protection”
Link: https://arxiv.org/pdf/2308.06932.pdf
“Devising and Detecting Phishing: large language models vs. Smaller Human Models”